别被(bèi)忽悠了!我來談談大數據平台的4個要點,你們寫的都(dōu)不是幹貨
公司要做數據分析,首先要考慮數據的準備,也就(jiù)是數據平台的建設,最近接觸了幾個朋友都(dōu)處于這(zhè)一環節,而且其中一個在方案選型過(guò)程中,也是充滿了糾結,而我也并沒(méi)有在開(kāi)始階段給出合理全面(miàn)的建議。
所以根據自己的認知整理了這(zhè)篇文章,一是對(duì)自己的整理,二是希望通過(guò)分享,給大家一些參考的價值。
一、爲何而搭建數據平台
業務跑的好(hǎo)好(hǎo)的,各系統穩定運行,爲何還(hái)要搭建企業的數據平台?
這(zhè)樣(yàng)的問題,心裡(lǐ)想想就(jiù)可以了,不要大聲問出來。我來直接回答一下,公司一般在什麼(me)情況下需要搭建數據平台,對(duì)各種(zhǒng)數據進(jìn)行重新架構。
從業務上的視角來看:
1.業務系統過(guò)多,彼此的數據沒(méi)有打通。這(zhè)種(zhǒng)情況下,涉及到數據分析就(jiù)麻煩了,可能(néng)需要分析人員從多個系統中提取數據,再進(jìn)行數據整合,之後(hòu)才能(néng)分析。一次兩(liǎng)次可以忍,天天幹這(zhè)個能(néng)忍嗎?人爲整合出錯率高怎麼(me)控制?分析不及時效率低要不要處理?
從系統的視角來看:
2.業務系統壓力大,而不巧,數據分析又是一項比較費資源的任務。那麼(me)自然會(huì)想到的,通過(guò)將(jiāng)數據抽取出來,獨立服務器來處理數據查詢、分析任務,來釋放業務系統的壓力。
3.性能(néng)問題,公司可以越做越大,同樣(yàng)的數據也會(huì)越來越大。可能(néng)是曆史數據的積累,也可能(néng)是新數據内容的加入,當原始數據平台不能(néng)承受更大數據量的處理時,或者是效率已經(jīng)十分低下時,重新構建一個大數據處理平台就(jiù)是必須的了。
上面(miàn)我列出了三種(zhǒng)情況,但他們并非獨立的,往往是其中兩(liǎng)種(zhǒng)甚至三種(zhǒng)情況同時出現。一個數據平台的出現,不僅可以承擔數據分析的壓力,同樣(yàng)可以對(duì)業務數據進(jìn)行整合,也會(huì)不同程度的提高數據處理的性能(néng),基于數據平台實現更豐富的功能(néng)需求。
二、數據平台的建設有哪些方案可以選擇
如果一句話回答的話,那就(jiù)是:太多了(這(zhè)是一句廢話,我承認),但确實有非常多的方案可供選擇,我懂的少,肯定是無法一一介紹,所以就(jiù)分成(chéng)了下面(miàn)幾類,相信也一定程度上覆蓋了大部分企業的需求了。
1.常規數據倉庫:它的重點在于數據整合,同時也是對(duì)業務邏輯的一個梳理。雖然它也可以打包成(chéng)ssas那種(zhǒng)cube一類的東西來提升數據的讀取性能(néng),但是數據倉庫的作用,更多的是爲了解決公司的業務問題,而不僅僅是性能(néng)問題。這(zhè)一點後(hòu)面(miàn)會(huì)詳細介紹。
2.敏捷型數據集市:
底層的數據産品與分析層綁定,使得應用層可以直接對(duì)底層數據産品中的數據進(jìn)行拖拽式分析。這(zhè)一類産品的出現,其初衷是爲了對(duì)業務數據進(jìn)行簡單的、快速的整合,實現敏捷建模,并且大幅提升數據的處理速度。
目前來看,這(zhè)些産品都(dōu)達到了以上的目的。但它的優缺點也比較明顯,從我的角度看,它是很難成(chéng)爲公司的數據中心的。
3.MPP(大規模并行處理)架構的數據産品,以最近開(kāi)源的greenplum爲例。
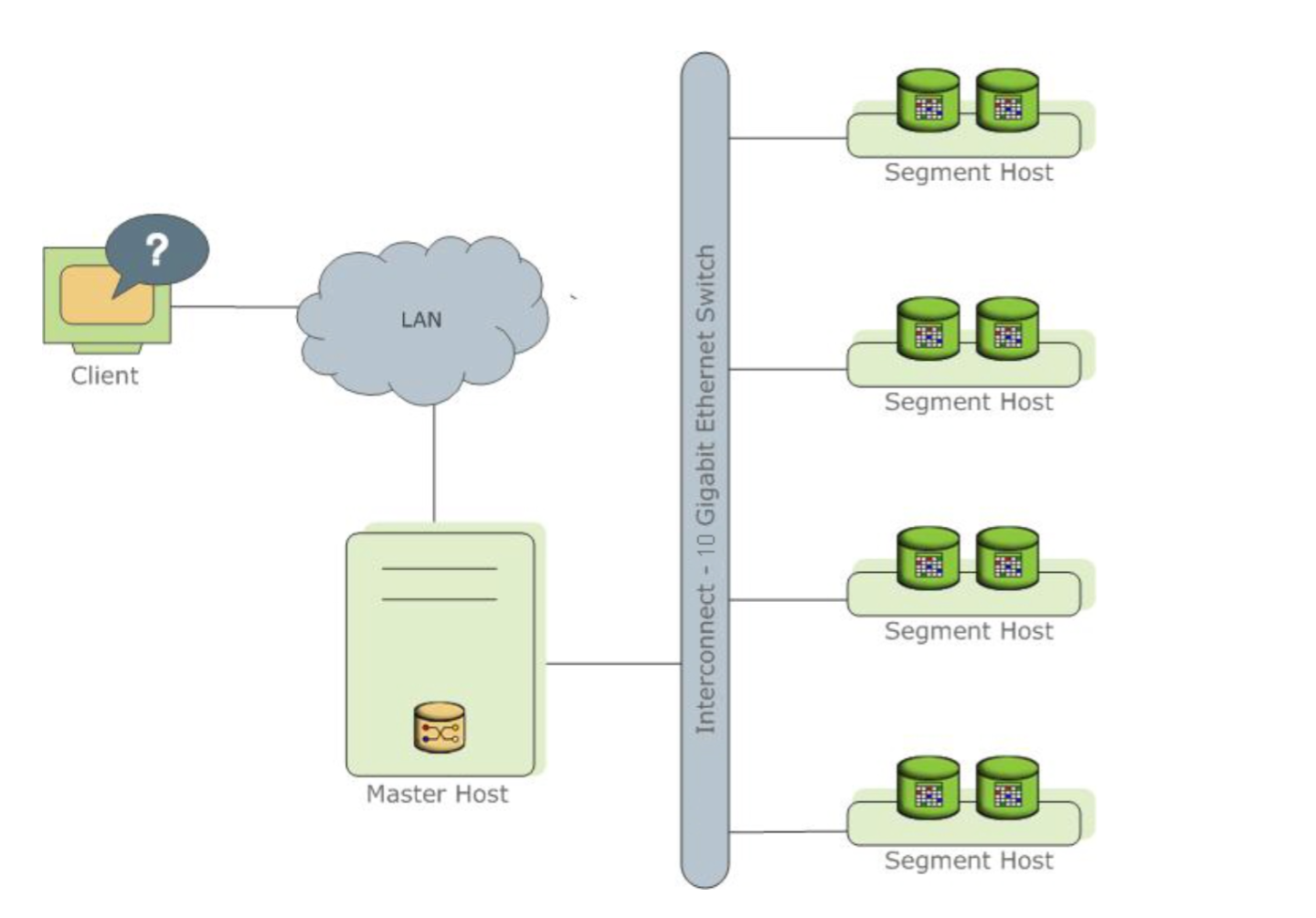
傳統的主機計算模式在海量數據面(miàn)前,顯得弱雞。造價非常昂貴,同時技術上也無法滿足高性能(néng)的計算,smp架構難于擴展,在獨立主機的cpu計算和io吞吐上,都(dōu)沒(méi)辦法滿足海量數據計算的需求。分布式存儲和分布式計算正是解決這(zhè)一問題的關鍵,不管是後(hòu)面(miàn)的MapReduce計算框架還(hái)是MPP計算框架,都(dōu)是在這(zhè)一背景下産生的。
greenplum的數據庫引擎是基于postgresql的,并且通過(guò)Interconnnect神器實現了對(duì)同一個集群中多個Postgresql實例的高效協同和并行計算。
4.hadoop分布式系統架構
關于hadoop,已經(jīng)火的要爆炸了,greenplum的開(kāi)源跟它也是脫不了關系的。有著(zhe)高可靠性、高擴展性、高效性、高容錯性的口碑。在互聯網領域有非常廣泛的運用,雅虎、facebook、百度、淘寶等等等等。
hadoop生态體系非常龐大,各公司基于hadoop所實現的也不僅限于數據分析,也包括機器學(xué)習、數據挖掘、實時系統等。
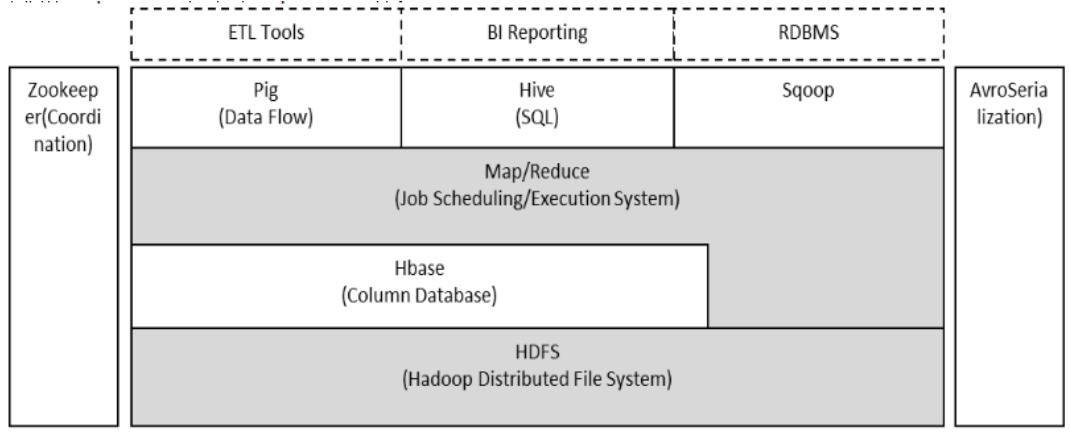
當企業數據規模達到一定的量級,我想hadoop是各大企業的首選方案,到達這(zhè)樣(yàng)一個層次的時候,我想企業所要解決的也不僅是性能(néng)問題,還(hái)會(huì)包括時效問題、更複雜的分析挖掘功能(néng)的實現等。非常典型的實時計算體系也與hadoop這(zhè)一生态體系有著(zhe)緊密的聯系。
近些年來hadoop的易用性也有了很大的提升,sql-on-hadoop技術大量湧現,包括hive、impala、spark-sql等。盡管其處理方式不同,但普遍相比于原始基于文件的Mapreduce,不管是性能(néng)還(hái)是易用性,都(dōu)是有所提高的。也因此對(duì)mpp産品的市場産生了壓力。
對(duì)于企業構建數據平台來說,hadoop的優勢與劣勢非常明顯:它的大數據的處理能(néng)力、高可靠性、高容錯性、開(kāi)源性以及低成(chéng)本(爲什麼(me)說低成(chéng)本,要處理同樣(yàng)規模的數據,換一個其他方案試試呢)。缺點也就(jiù)是他的體系的複雜,技術門檻較高(能(néng)搞定hadoop的公司規模一般都(dōu)不小了)。
關于hadoop的優缺點對(duì)于公司的數據平台選型來說,影響已經(jīng)不大了。需要上hadoop的時候,也沒(méi)什麼(me)其它的方案好(hǎo)選擇(要麼(me)太貴,要麼(me)不行),沒(méi)到達這(zhè)個數據量的時候,也沒(méi)人願意碰這(zhè)東西。總之,不要爲了大數據而大數據。
三、方案很多,企業要怎樣(yàng)選擇呢
環境太複雜,但是我想至少要從下面(miàn)這(zhè)幾個方面(miàn)去考慮吧。
1.目的:什麼(me)樣(yàng)的目的?就(jiù)是文中開(kāi)始部分的三種(zhǒng)情況,或者是其中幾個的組合。
做事(shì)方法都(dōu)一樣(yàng),哪怕是中午出去吃飯,也是要在心裡(lǐ)有個目的,這(zhè)頓飯是爲了吃飽,還(hái)是吃爽,或者爲了拍别人的馬屁,然後(hòu)才好(hǎo)選擇去吃什麼(me)。
當然,要明确數據平台的建設目的,哪裡(lǐ)是那麼(me)容易的,初衷與讨論後(hòu)确認的目标或許是不一緻的。
公司要搭建一個數據平台的初衷可能(néng)很簡單,隻是爲了減輕業務系統的壓力,將(jiāng)數據拉出來後(hòu)再分析,如果目的真的就(jiù)這(zhè)麼(me)單純,還(hái)真的沒(méi)有必要大動幹戈了。
如果是獨立系統的話,直接將(jiāng)業務系統的數據庫複制出來一份就(jiù)好(hǎo)了;如果是多系統,快速建模,直接用finebi或者finereport接入進(jìn)去就(jiù)能(néng)實現數據的可視化與olap分析。

(此處已添加小程序,請到今日頭條客戶端查看)
但是,既然已經(jīng)決定要將(jiāng)數據平台獨立出來了,就(jiù)不再多考慮一點嗎?多個系統的數據,不趁機梳理整合一下?當前隻有分析業務數據的需求,以後(hòu)會(huì)不會(huì)考慮到曆史數據呢?這(zhè)種(zhǒng)敏捷的方案能(néng)夠支撐明年、後(hòu)年的需求嗎?
任何公司要搭建數據平台,都(dōu)不是一件小事(shì),多花一兩(liǎng)個月實施你可能(néng)覺得累,多花一周兩(liǎng)周的時間,認真的思考一下總可以的吧。雷軍不是說過(guò)這(zhè)樣(yàng)一句話:不能(néng)以戰術上的勤奮,掩蓋戰略上的懶惰。
2.數據量:根據公司的數據規模選擇合适的方案,這(zhè)裡(lǐ)說多了都(dōu)是廢話。
3.成(chéng)本:包括時間成(chéng)本和金錢,不必多說。但是這(zhè)裡(lǐ)有一個問題想提一下,發(fā)現很多公司,要麼(me)不上數據平台,一旦有了這(zhè)樣(yàng)的計劃,就(jiù)恨不得馬上把平台搭出來用起(qǐ)來,時間成(chéng)本不肯花,這(zhè)樣(yàng)的情況很容易考慮欠缺,也容易被(bèi)數據實施方忽悠。
關于方案選擇的建議,舉以下3+1個場景
場景a:要實現對(duì)業務數據的快速提取和分析,多個業務系統,沒(méi)有達到海量數據,不考慮曆史數據,不需要依照業務邏輯對(duì)數據進(jìn)行系統的梳理,這(zhè)種(zhǒng)情況下,可以考慮敏捷型的bi工具自帶的數據底層。
簡單來講,這(zhè)種(zhǒng)場景僅僅是在技術層面(miàn)上,完成(chéng)對(duì)數據的整合與提速,并沒(méi)有從業務層面(miàn)上對(duì)數據進(jìn)行建模。他可以滿足一定的分析需求,但是不能(néng)成(chéng)爲公司的數據中心。
場景b:要搭建公司級的數據中心,打通各系統之間的數據。非常明顯的,需要搭建一個數據倉庫。這(zhè)時就(jiù)需要進(jìn)一步考慮公司數據的量級了,如果是小數據量,TB級以下,那麼(me)在傳統數據庫中建這(zhè)樣(yàng)一個數據倉庫就(jiù)可以了,如果數據量達到幾十上百TB,或者可見的在未來幾年内數據會(huì)達到這(zhè)樣(yàng)一個規模,可以將(jiāng)倉庫搭在greenplum中。
這(zhè)種(zhǒng)場景應該是适用于大部分公司,對(duì)于大部分企業來說,數據量都(dōu)不會(huì)PB級别,更多的是在TB級以下。
場景c:公司數據爆發(fā)式增長(cháng),原有的數據平台無法承擔海量數據的處理,那麼(me)就(jiù)建議考慮hadoop這(zhè)種(zhǒng)大數據平台了。它一定是公司的數據中心,這(zhè)樣(yàng)一個角色,倉庫是少不了的,可以將(jiāng)原來的倉庫直接搬到hive中去。
這(zhè)種(zhǒng)數據量比較大的情況要怎樣(yàng)呈現,因爲hive的性能(néng)較差,它的即席查詢可以接impala,也可以接greenplum,因爲impala的并發(fā)量不是那麼(me)高,而greenplum正好(hǎo)有它的外部表(也就(jiù)是greenplum創建一張表,表的特性叫(jiào)做外部表,讀取的内容是hadoop的hive裡(lǐ)的),正好(hǎo)和hadoop完美的融合(當然也可以不用外部表)。
場景d:這(zhè)個是後(hòu)面(miàn)補充的,當公司原本有一個數據倉庫,但曆史數據了堆積過(guò)多,分析性能(néng)下降,要怎麼(me)辦?兩(liǎng)個方案可以考慮,比較長(cháng)遠的,可以將(jiāng)倉庫以及數據遷移到greenplum中,形成(chéng)一個新的數據平台,一個獨立的數據平台,可以産生更多的可能(néng)性;比較快速的,是可以將(jiāng)類似finecube那種(zhǒng)敏捷型數據産品接入原來的倉庫,這(zhè)樣(yàng)來提升數據的處理性能(néng),滿足分析的要求。
四、關于方案選型時可能(néng)會(huì)出現的誤區
忽略業務的複雜性,要用工具來解決或者是繞開(kāi)業務的邏輯。
這(zhè)個是我最近遇到過(guò)的,客戶要做報表平台,有三個業務系統的數據需要整合。但是急于變現,不想搭建傳統的數據倉庫,所以從敏捷型的bi工具中選型。工具廠商對(duì)自己數據産品的描述,一般著(zhe)重于它的快速實施、性能(néng)的優化、以及自帶的基本etl功能(néng)。這(zhè)樣(yàng)容易給客戶造成(chéng)誤區,就(jiù)是通過(guò)這(zhè)一産品可快速搭建出一個公司級别的數據中心,滿足于頂層對(duì)數據的需求。
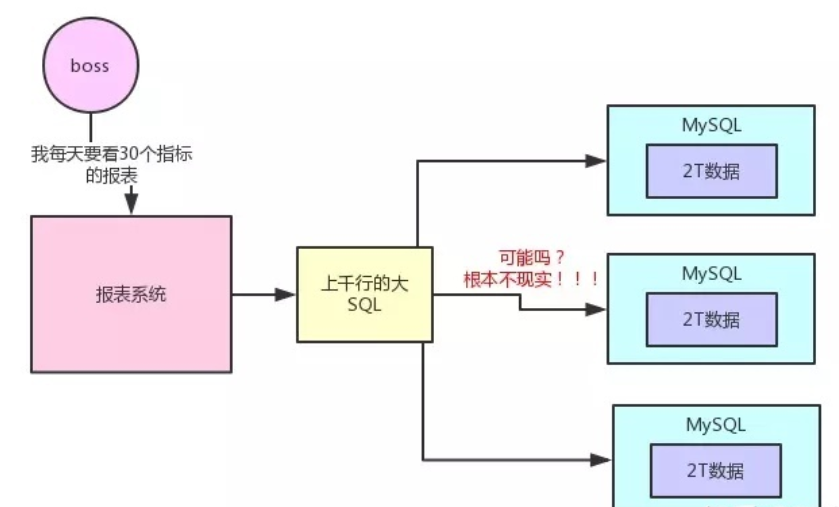
然而在後(hòu)期突然意識到,工具所解決的,僅僅是在技術層面(miàn)上簡化了工具的使用的複雜性,把etl和數據集市封裝在一起(qǐ),并且提高了數據的性能(néng),但是并沒(méi)有從業務層面(miàn)上實現數據的建模,很多細節問題無法處理。
雖然敏捷開(kāi)發(fā)非常誘人,如果業務系統簡單,或者隻需要分析當前狀态的業務數據,不需要公司級的數據中心,那麼(me)确實是一個非常好(hǎo)的方案。然而這(zhè)些問題還(hái)沒(méi)有考慮清楚,對(duì)敏捷産品有了過(guò)高的期望,後(hòu)面(miàn)是會(huì)遇到些麻煩的。
除此之外,可能(néng)還(hái)會(huì)有爲了大數據而大數據的,但是這(zhè)些我在實際的工作中還(hái)沒(méi)有遇到。
最後(hòu)總結一下,企業選擇數據平台的方案,有著(zhe)不同的原因,要合理的選型,既要充分的考慮搭建數據平台的目的,也要對(duì)各種(zhǒng)方案有著(zhe)充分的認識。
僅從個人的角度,對(duì)于數據層面(miàn)來說,還(hái)是傾向(xiàng)于一些靈活性很強的方案的,因爲數據中心對(duì)于公司來說太重要了,我更希望它是透明的,是可以被(bèi)自己完全掌控的,這(zhè)樣(yàng)才有能(néng)力實現對(duì)數據中心更加充分的利用。因爲,我不知道(dào)未來需要它去承擔一個什麼(me)樣(yàng)的角色。
ps:數據平台的建設,是一個不小的項目,實施周期過(guò)長(cháng),會(huì)不會(huì)途中夭折?這(zhè)鍋誰都(dōu)不想背,這(zhè)樣(yàng)的項目,怎樣(yàng)才能(néng)叠代起(qǐ)來,逐步實施逐步投放?




 關注官方微信
關注官方微信